
In the previous parts 1, 2 and 3 of this series, we covered the basics of encryption, walked through a live example of a ransomware in detail, and talked about encryption weaknesses. In this part of the encryption 101 series, we will begin wrapping it up by going into detail on a ransomware with weak encryption and walking through step-by-step the thought process of creating a decryptor for it.
This article is intended to help give a malware analyst a starting point for which to build off of in order to reverse and break ransomware encryptions. If nothing more, this article is to serve as an explanation why it is still worth it to inspect ransomware in detail to try to find opportunities for decryption.
Even though encryption packages and API’s are built into modern day operating systems, still, many malware authors manage to misuse them and give us (analysts) the opportunity to exploit their poor coding skills.
Target ransomware intro
The sample we will be talking about in detail is PrincessLocker. Credit to Hasherezade for analyzing and creating keygen and decryptor for this. Her code and information on using the decryptor, should you need to, can be found here:
Princess Locker decryptor
Before continuing on, I greatly urge you to read the analysis report on this ransomware so that you are familiar with some of its inner workings before talking about the decryption. The blog post can be found below:
/blog/threat-analysis/2016/11/princess-ransomware/
Analysis
Because this is not a lesson in unpacking, let’s assume that you have just read an analysis talking about
PrincessLockerbeing unpacked and some basic functionality, the following hash of the unpacked sample was provided:
4142a59be1f59dbd8e1be832df893d08
as well as the original packed hash
14c32fd132942a0f3cc579adbd8a51ed
We will start with the unpacked sample for our static analysis and will be using the fully packed sample for any dynamic analysis we have.
Static
Since we are focusing strictly on the crypto portion of the code, let’s start by doing a search and cross-reference for some crypto string or APIs, we see CryptDeriveKey being used in function address 10007980.

The parameter passed into CryptDeriveKey for algorithm ID is 0x660E, which translates to CALG_AES_128.
So we know that there is an AES key being generated right there, the “password” for this AES key is the pHash variable. If we trace it back, we see it being passed into 10007BB9, the call esi instruction. The strings are obfuscated so we cannot easily find them statically here. So we go to the debugger with the fully packed file 14c32fd132942a0f3cc579adbd8a51ed.
Debug
When dealing with the packed file, to get to the unpacked code I am looking for, I typically find an API call from the unpacked sample and set a breakpoint in the library code. If we go to the main function who gets called and leads us to this derive key call, we see it is the exported function “Zero“.
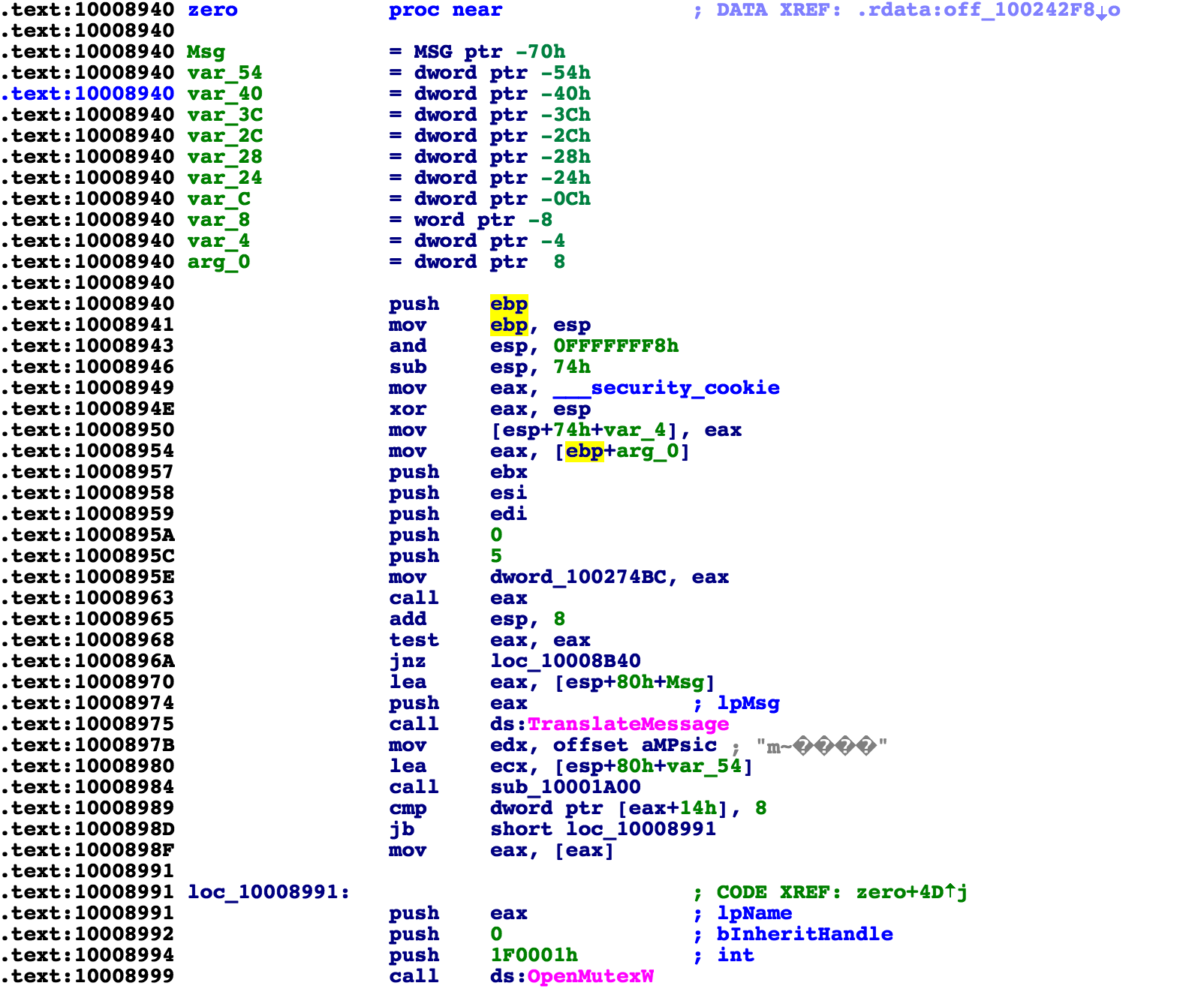
Two candidates here for the breakpoint are TranslateMessage and OpenMutexW. I didn’t have luck with TranslateMessage, so I now try OpenMutexW.
If you have the StringOD plugin in Olly, pressing control + G brings up this menu:
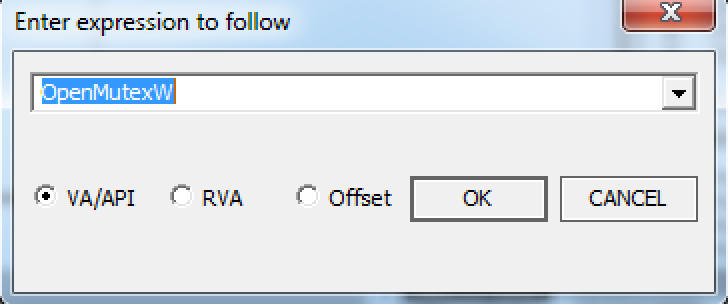
Here I enter the API call I want to break and it will take me into the library code, I can set a breakpoint here and click run until I hit this breakpoint, then follow until the return of this function which will bring me to the point in this unpacked file now so we can debug.
If we continue on and break at the call esi where we were at before, we see that it is cryptHashData, so, we have lpString being hashed and the output hash of that string being used for input in generating AES key.

Static
If we trace the lpString to where it comes from in IDA, we see that it is the parameter arg_0 of this function, and it also looks to be a randomly generated string.Going out of this function one level, we see this line:
10008B11 lea ecx, [esp+98h+var_54] 10008B15 call sub_10007980
The var_54 is the argument which was being used in the function we just looked at. It is the string who gets hashed and used for AES key. Following it backward, I am trying to see where this variable might get populated. I can set a breakpoint on memory write for this address in olly, but also, in this case, it is easy enough to find by just looking in a few of the functions which use it as a parameter earlier.
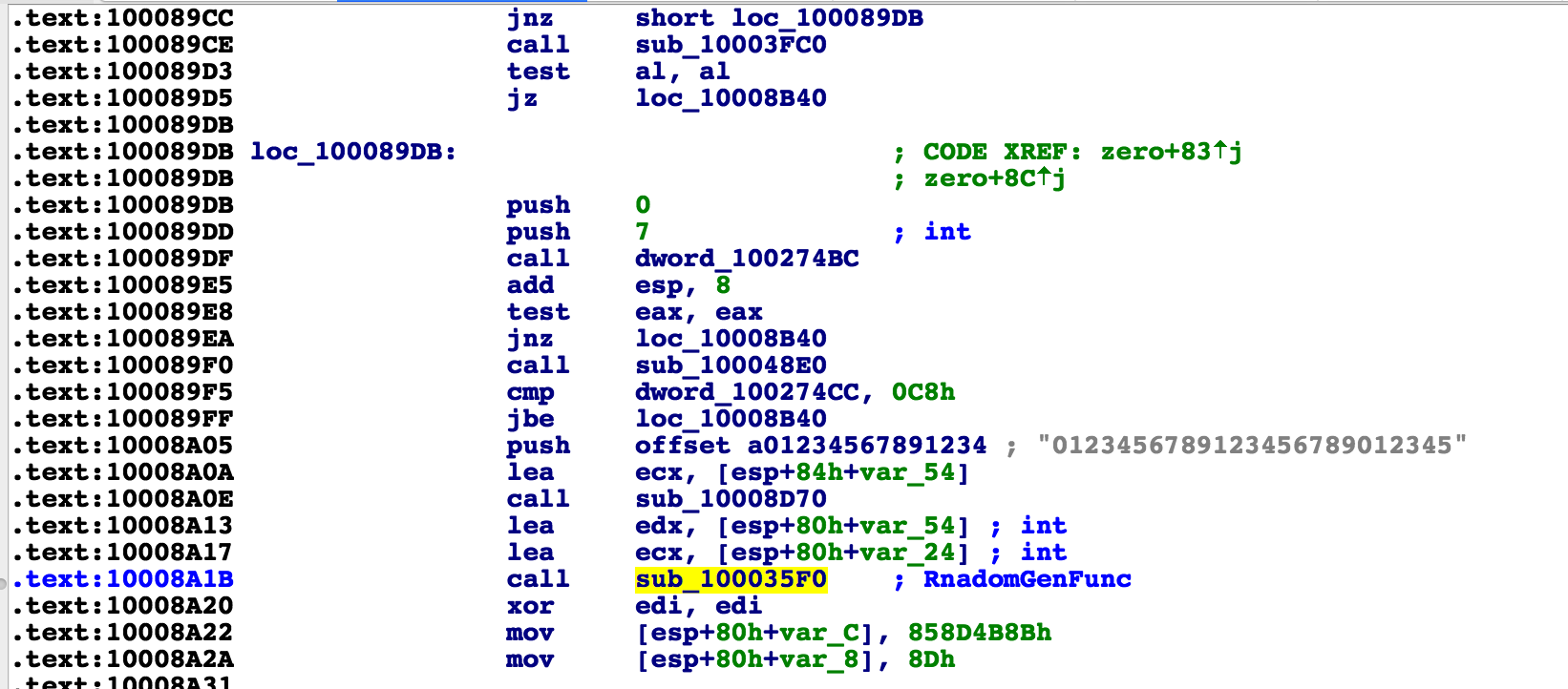
I come across this function which is highlighted. I have commented it as RandomGenFunc. It takes as a parameter in edx, the variable which was used below to generate the key. So hopefully this is where the variable gets populated and the random password string gets created.
We see off the bat, that it uses srand() with a seed value of time64(). I will include the description of what exactly time64 to make sure there is no confusion.
If we look around in various sub-functions, we see this behavior being used in a loop. srand() is called again with a seed of time64() and then in a loop, rand is being called to generate a new number.

What you are seeing here is the seeding of a number with the current time, and if you recall the functionality of srand() and rand(), the seed parameter is what determines the set of random numbers that each call to rand() will output. So, if the seed is the same, the sequence will also be the same. THIS IS THE KEY WEAKNESS FOR US TO EXPLOIT.

As you can see, a random charset “0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabc…” being used and inside of a loop, rand() is being called over and over again. A string is being built by taking that position as a substring of the charset, char by char.
So, now we have our starting point. We know that the AES key is being generated by a random string who is being created by a seed of current time. If we can find the current time which was used during the encryption, we know that we can reproduce the AES key. This can almost definitely be brute forced within a reasonable amount of time.
If you recall the previous lesson, we talked about almost exactly this scenario. Please read that lesson if you have not done so already.
Overview of encryption code weakness
For now, our analysis phase is basically complete. We did not see any more calls to rand() or srand() aside from the one in the loop we spoke of in function 10001CC0, so we can focus on those. As we can see, this function is being called 3 separate times.
This makes sense because there are 3 sets of random strings being generated in this malware.
- AES key
- Victim ID
- File Extension
The first call is for the loop which is generating the random string, used as a key. We can confirm this by debugging and seeing this memory region being passed into the function who generates AES key. The second call, we can confirm is the victim ID. We can verify this because the parameter passed in through edx for the length is 0x0C, or 12.

If we look at the number and compare it to the website presented from the ransomware, we see that this for the number that gets generated for the victim ID is also 12 in length.
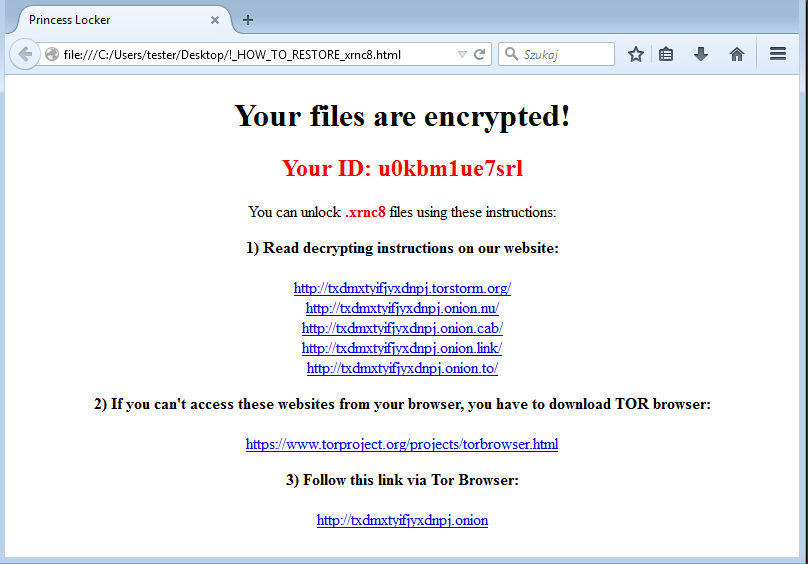
Which leaves the last call to this random string generator function to be the file extension.
The difference in these 3 sets of random number seeds are close by in code so it can be assumed that they might be only a few seconds apart in execution.
Understanding the weakness
What all this means to us is that our saving grace here is the fact that the ransomware author used the same random number generating logic for the file extension and victim ID as they did the AES key. If this was not the case, (if they used a constant static extension and something else for victim ID) we would have nothing to go off of.
I’ll explain what I mean here. It is not feasible to generate AES keys and test encrypt a file for thousands of iterations (potential seed seconds). The computation time is too great. We must find the string match for the victim ID, which is a relatively fast computational operation, and then we can begin generating test AES keys incrementally at that point because we then know that there will only be no more than 100 seconds of difference between the time that the victim ID was generated and the AES key. Generating an AES key 100 times is doable and reasonable.
If the victim ID and extension were not also random strings, the only alternative would be that we might be able to decrypt the files only if we had a roughly accurate time of infection, which would work quite well too.
We could then do exactly as I mentioned in the example from the previous blog part, and do a very targeted seconds seed. But this would require that every victim would have to be able to figure out roughly within a minute or two when they were infected. This is a perfectly good solution for a company building a decryptor after being hit by ransomware, but for building a generic tool that can work on any victim easily, hasherezade’s method is much better.
So back to the situation at hand, if we can find the seed value (calendar seconds) used for generating the file extension or the victim ID, we can cycle back the counter from those seed values, and within a reasonably short range, we will hit the seed value used for generating the encryption key. Again, the reason this is true is because the time64() srand() was called first for the AES key, and then soon after called for the other two.
So where does this leave us? We must now figure out a way to find the exact second that the victim ID or extension was generated.
Decryption algorithm steps
As the final part to the brainstorming of the algorithm, I will list out, step by step, what we want the algorithm to do and why.
- Create a seed value in calendar seconds, and call srand() with it.
- From the user, request either the victim ID from the ransom note, the encrypted file extension, or both.
- Start incrementally counting down in seconds from now calling srand()
- For each srand() iteration, replicate the same rand() calls/substring charset lookup as the ransomware.
- Generate a 12 character long string and compare it to the user provided victim ID
- If no match, decrement the calendar time variable and try again.
- If matched, this means we have found the second which the victim ID was seeded. Thus, we are most likely very close in the seed time for the AES key. lets set a test limit of 100 seconds of iteration. (We know that the AES key was generated most likely within a few seconds before the victim ID)
- We decrement the time pointer now, but for each iteration, we are actually generating a password for the AES key, generating the actual test AES key, and performing an AES decryption of an encrypted file using that key, then comparing the output to a known original version of that file.
- If it matches, then it is highly likely we have found the key and we can apply it to the rest of the file on the hard disk.
- If it does not match, that might mean that there just happened to be a massive coincidence in that the seed generated a duplicate sequence of numbers. So, we go back and start the process over from step 3 -> 1 continuing down in seconds.
Some things worth mentioning here about this is that we are counting down in seconds from the time our decryption tool is run until the time the victim files were encrypted, the longer time passes, the longer the tool will take.
But again, it is worth noting that the operation of generating a 12 character random string and doing a string comparison to victim ID is very fast, which is why it is not such a horrible thing to say that we might iterate 500,000 times because this comparison can be done 100’s if not 1000’s of times per second. So, even if the file was encrypted a month ago, it wouldn’t be an unreasonable wait time.
Once it is matched, the computationally intensive AES generation and decryption operations are only performed 100 times or less. This is how we can keep decryption key search time closer to a constant.
Conclusion
In this, part 4 of the series, we now have a solid understanding of how the encryption code works for this sample and more importantly, what is wrong with the encryption scheme that allows us to exploit it. We walked through the thought process of reversing the decryption to the point of looking for weaknesses, and we now also have a game plan for building the decryption tool.
Where do we go from here? Tune in for part 5, the final part of the encryption 101 series where we will put it all together and walk through the source code of the completed decryption tool in detail.








