
We have reached the final installment of our Encryption 101 series. In the prior post, we walked through, in detail, the thought process while looking at the Princess Locker ransomware. We talked about the specific ways to narrow down the analysis toward the encryption portions, the weaknesses in this specific encryption scheme, the potential options we might have for decryption, and finally we made a game plan for creating a decryption tool.
To continue off of that point, and to close off this series, we will be walking through the source code of the Princess Locker decryption tool, which my colleague hasherezade has created. After Part 4 of our series, you could have most likely used that information to create your own tool. However, just to solidify everything and make sure it all clicks, I will explain the details of this already functioning tool, as I believe it is much easier to understand something and create your own tools in the future if you see how an already-functioning one works.
The process of reversing engineering the encryption code and forward engineering the decryption code essentially covers the same point from multiple angles.
Code overview
Let’s first walk through all the functions in this program at a high level and do a quick overview of what they are and how they are used together. This will help the specific lines of code within each function make more sense when we are going through in detail.
The full source code of this tool is available here: Princess Locker decryption tool source code. I strongly recommend you follow along with full source code open in another window as you read this article.
Lets start from the top of the main.cpp file.
#define CHARSET "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
If you remember from when we were analyzing the RNG portion of Princess, the numbers being generated were used as an index to look up a letter in this string. So, if the random number 38 was generated, it would have added the letter “c” to the victim ID string, since the “c” is at the 38th position if this is treated as an array. This is what the CHARSET is here.
Below is a list of the major functions that are worth talking about:
find_key dump_key check_key find_start_seed find_seed find_key_seed find_uid_seed make_key
Any of the other functions I did not mention here because they are either not directly related to the decryption/key searching, or they are just self explanatory. For instance, read_buffer is literally what it sounds like: It is a helper function that reads a buffer in from a file. This is used within some of the above functions, but it is not worth talking about specifically in detail.
find_key – Incrementally generates key with seed value, decrypts file, and checks against original file dump_key – writes key out to file check_key – uses a potential key, decrypts file with it, and checks it against the original version find_start_seed – wrapper function; calls others to find seed value which was used for UID or ext find_seed – incrementally test seeds, generate random strings to verify against UID find_key_seed – NOT USED, wrapper for find_seed with direction find_uid_seed – wrapper for find seed, setting isKey param to false
Of all of these, the find_seed and find_key are the two functions that are doing the major portion of the work.
Main function
Now let’s start from the wmain() function and walk through all the logic in detail.

We will skip past to the line on 314, printf(“Searching the key…“);
Everything pictured above is just input checking to make sure everything that is needed was provided properly.
The rest of the main is below:

The next line is DWORD init_seed = time(NULL); This is just getting the current time. This will be the first seed we test against. We know from Part 4 that the current time was the only input being used to seed the random number generator. So, we will be using the current time and decrementing this doing our test key generation as we go on.
do { DWORD uid_seed = find_start_seed(unique_id, extension, init_seed); key = find_key(filename1, filename2, check_size, uid_seed, limit); init_seed = uid_seed - 1; } while (!key);We see the find_start_seed function being called. The parameters unique_id, extension, init_seed at this point are the following in order: ransom note ID or NULL if none is used, random file extension, which Princess added on, and current time. As the loop progresses, the init_seed is decremented because we essentially are trying to find the exact second when the Princess infection occurred on these files.
There are three different second values which were used for seeding each of the RNG uses. As I mentioned in the previous post, they are the extension, the UID, and the AES key password. Once we find one of these, the others are very close by in time, so we can easily find the others.
Let’s look at the details of find_start_seed before continuing on. Let’s assume we are passing in a UID we got from the ransom note.
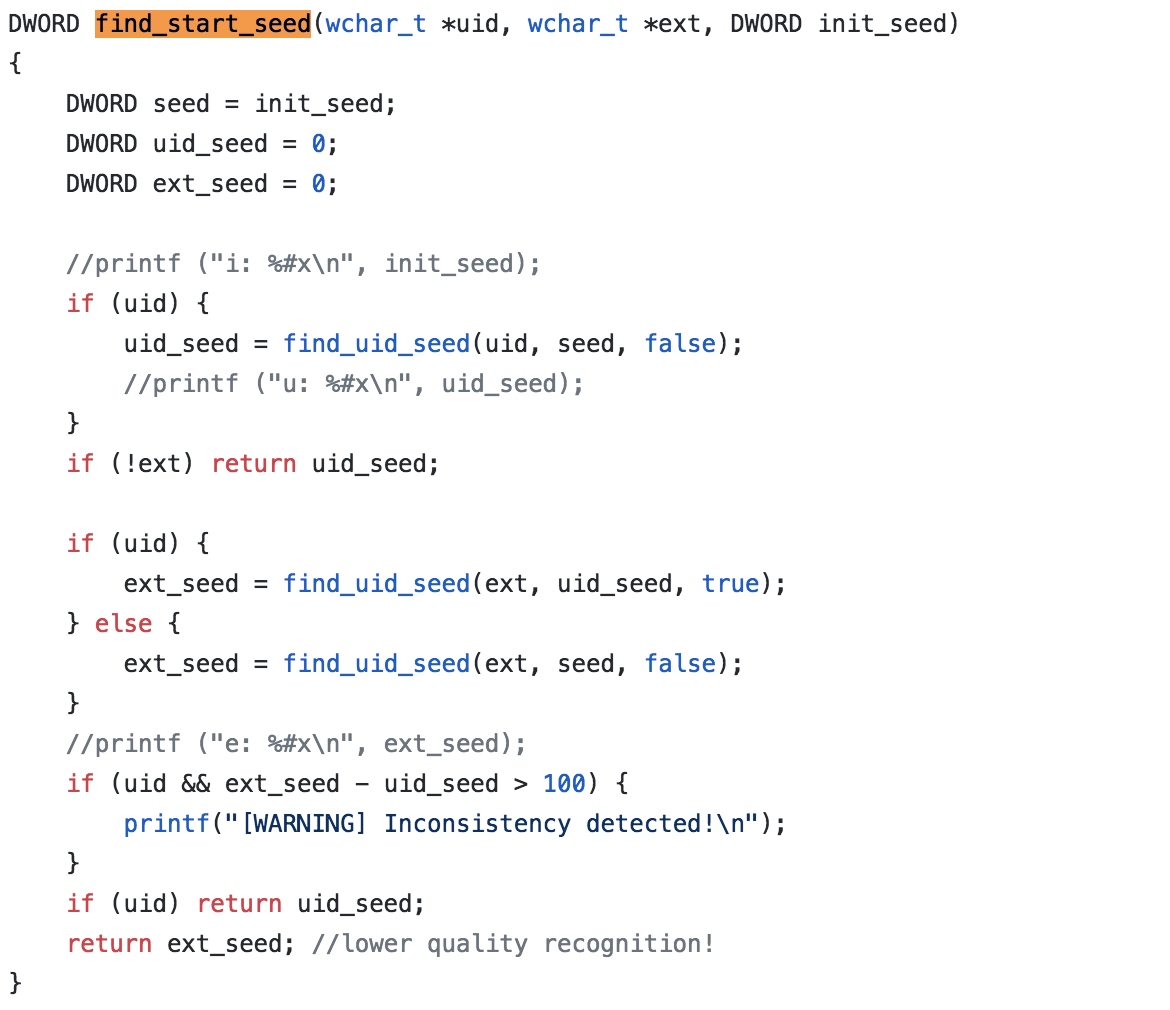
The first call you see inside of here is the find_uid_seed(). This is a wrapper function to find_seed(), which is the main workhorse. The false boolean variable passed in is telling it to decrement when searching for the UID value. This makes sense because the seed we start with here is the current time, so obviously the infection has occurred in the past.
Before going into the details of the find_seed function, I’ll just go over a high level of what’s going on in the rest of this function. The result of find_uid_seed function will be the seed value, a.k.a the exact second which the RNG was seeded, to generate the ransom note ID during the infection.
You’ll notice the “if” for UID variable. This is here because the ransom ID is not a requirement. It is here to make the result more sure. If someone did not have their ransom ID referred to as UID, then they can still try to decrypt with just their file extension.
The reason this works is because the UID was one RNG seeding during infection, the random file extension was another, and the actual AES password was the third. So having either the extension or the UID should be enough to be able to find the AES password seed. If you do have both, however, you make it that much more verified. Like a double verification.
Next we have the extension part:
if (uid) { ext_seed = find_uid_seed(ext, uid_seed, true); } else { ext_seed = find_uid_seed(ext, seed, false); }What’s going on here is if UID was passed in, that means that we have found the seed value for UID. If that is the case, we can use that seed value (the time which the UID RNG was seeded) as the starting point for looking for the extension seed. In the analysis of Princess Locker from Part 4, we saw that the UID was seeded first and then very soon after the extension RNG was seeded. So we can expect that the two seeds will be close in value.
This is why the true variable is passed in here. We are starting from the UID seed time and now counting forward to find the extension seed time. Now, if the UID was not provided by the user here, you see the same call is made with the false variable passed in. The seed is now the current time seed, which means we are just counting back from now until we find a seed match for the extension.
if (uid && ext_seed - uid_seed > 100) { printf("[WARNING] Inconsistency detected!n"); }After it has found both the UID seed time and the ext seed, it then does this final check and makes sure that the difference is less than 100. The reason for this is again that during the Princess Locker execution, the UID seed is generated, and then very shortly after in code flow, the ext seed is generated. If these two times are more than 100 seconds apart, something strange is occurring.
DWORD find_uid_seed(wchar_t* uid, DWORD start_seed, bool increment = true) { return find_seed(uid, start_seed, increment, false); }As I said before, find_uid_seed is just a wrapper for sind_seed, which is the main code that does the seed searching. So let’s go into that now.

After some variable initialization, we have the main loop of the function:
while (true) { srand(seed); What’s going on in this loop in general is a recreation of the random number generation portion of the ransomware itself. This is why it starts with srand(seed). The seed is the time passed in. This will determine the sequence of numbers that comes after by using the rand call.
So in the loop we are building, the string by taking the random number as the index into the charset. If the number being generated does not match with the UID provided by the user, it knows that the seed is not correct, so it will decrement the time and try again.
If this function was being called to find the ext after it already found the UID in a previous call, the seed time would be incremented. Here is a picture of the timeline so you can understand when and why we increment vs. decrement in various stages.
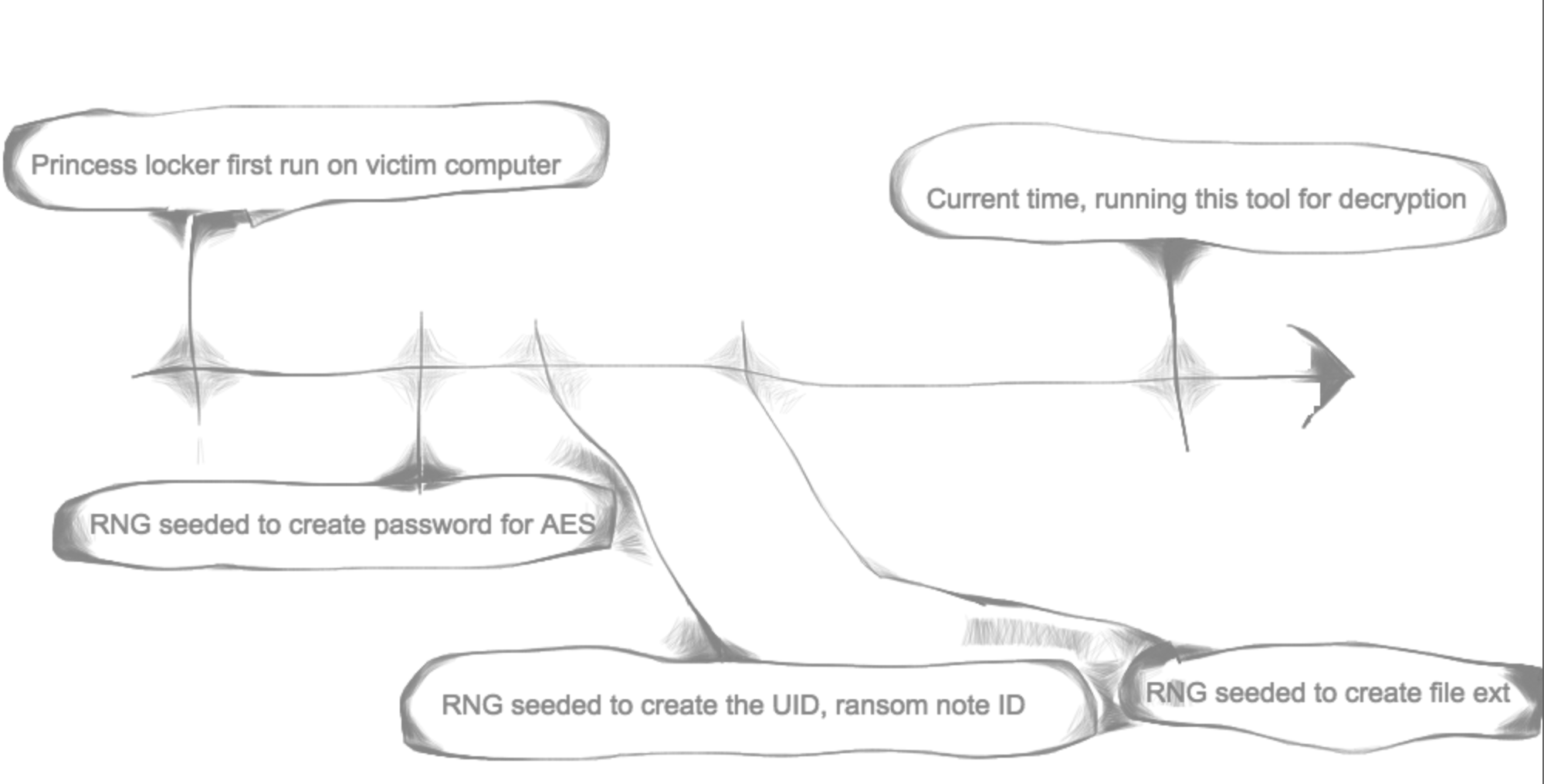
So, the stage that you are starting from will determine if you pass true or false into this find_seed function to make it decrement time or increment time.
Back to main function
Now that we have covered the details of the find seed functions, let’s get back to the main function after the find_start_seed where we left off.

The find_start_seed is a series of loops in itself. So after this call, most likely, it will have found a working seed value. If both ransom ID and ext were provided, it will return the UID seed as it is closer in timeline to the AES password seed.
Otherwise, if the UID was not provided, it will return the seed it found for the extension. If we look at the timeline, we see that the UID seed time occurred after the AES seed time. This means that we will need to do a couple things in a loop:
- decrement the seed one by one
- attempt to generate a AES password using the random seed
- decrypt the encrypted test file
- check it against a known clean version
So let’s now take a look at the find_key function and talk about the mentioned steps here in detail.
wchar_t* find_key(IN wchar_t *filename1, IN wchar_t *filename2, size_t check_size, DWORD uid_seed, DWORD limit=100)
Again, I’ll skip past the initial parts of the code that are just doing some reading and error checking. We get to the interesting parts at line 234.

Setting the key_seed variable to the moment in time which the ransom note ID was generated, we found this with find_start_seed and passed it into the find_key function.
do { key = make_key(MAX_KEY, key_seed, true); The first line in the loop for finding the keys here is the make_key call. I will not go into much detail here because it is not too different from how we generated UID or ext. It is just taking a seed and creating a random string the size of the ransom note ID using indexes to the charset string.
Next is a small loop for actually creating the AES key password and hashing it, which is what Princess Locker does. It does not use the randomly-generated password on its own. It created a random string and hashed it using sha256, then it used that as the key. Finally, it checked the key by decrypting.
for (key_len = MIN_KEY; key_len <= MAX_KEY; key_len++) { if (check_key(in_buf, expected_buf, check_size, key, key_len)) { printf("nMatch found, accuracy %d/%dn", check_size, BLOCK_LEN); key[key_len] = 0; found = true; break; } }The check_key function performs the following:
aes_decrypt(inbuf, outbuf, BLOCK_LEN, key_str, key_len)
It's creating an AES encryption using the test random-generated password, and seeing if it worked properly.
You may ask: Why waste time doing all the checks for the other RNGs? Why find the ext and the UID seed, when we could just start with the current time and decrement, testing if the seed works with a test AES decryption?
We could do this in theory. However, it is much faster of an operation to do a string comparison (which is all we need to do to find the UID seed) compared to:
- Generating a random string
- Hashing the string
- Creating AES key
- Encrypting data
- Checking against clean file
This is a lot more computationally intensive and would make the relatively fast UID search take much much longer.
Because the AES key was generated during the Princess Locker execution, and the ransom note ID was generated immediately after, once we find the ransom note ID (UID), we can then expect there will only be a few seconds of difference between these two seeds. So, this loop should only need to run a few times doing the encryption checks. Hopefully, you understand the efficiency of doing it the way that hasherezade has chosen.
Finishing off the find)key function, we basically just have some checks now, making sure it found the right key. If not, it will keep looping and decrementing the counter until it either finds it or hits a set limit.
Which brings us to the final portion of the main function at line 320:
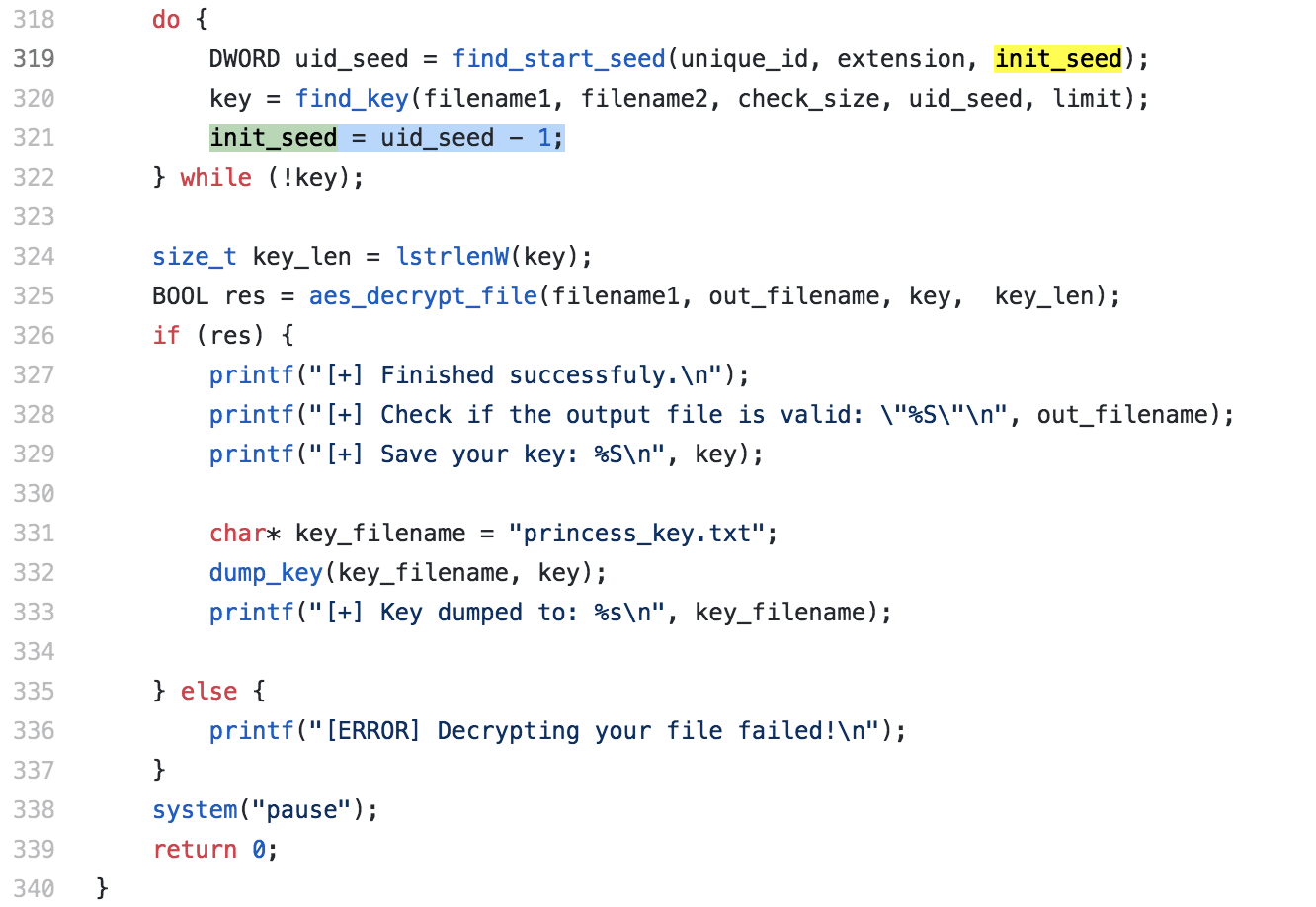
If for whatever reason, it never found the correct AES password within the limit set, it most likely means that the seed time was not correct for the UID. So it will start over from the initial seed of one less than where it left off, and start this whole process over again. It will continue this until it finds a UID seed that works and a password seed close by.
Conclusion
Hopefully, this series has brought you up to speed on the art of finding exploits in ransomware encryption and creating decryption tools for them. Now, this is not to say that if you master this specific weakness and this decryption tool, that it is easy to find and create one for a new ransomware. But, this is a step toward mastering one of the core skills.
Just like with exploit development/bug hunting, there are some core concepts and generic weaknesses that exist. The difficult/fun part is understanding the twists of those core concepts that any individual might come up with while creating their programs. It is about seeing the same concept or technique being used in an unfamiliar way, but ultimately understanding and identifying what the underlying mentality or technique is.
The important part is to understand the concepts. After that, it is a mix of creativity and thinking outside of the box to be able to identify and create your own exploits, or in our specific case, cracks for the ransomware encryption.








